1. 你了解的消息队列
生活里的消息队列,如同邮局的邮箱,如果没邮箱的话,邮件必须找到邮件那个人,递给他,才玩完成,那这个任务会处理的很麻烦,很慢,效率很低但是如果有了邮箱,邮件直接丢给邮箱,用户只需要去邮箱里面去找,有没有邮件,有就拿走,没有就下次再来,这样可以极大的提升邮件收发效率!
rabbitmq是一个消息代理,它接收和转发消息,可以理解为是生活的邮局。 你可以将邮件放在邮箱里,你可以确定有邮递员会发送邮件给收件人。 概括: rabbitmq是接收,存储,转发数据的。 官方教程:http://www.rabbitmq.com/tutorials/tutorial-one-python.html
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
2. 公司在什么情况下会用消息队列?
1.电商订单
想必同学们都点过外卖,点击下单后的业务逻辑可能包括:检查库存、生成单据、发红包、短信通知等,如果这些业务同步执行,完成下单率会非常低,如发红包,短信通知等不必要的流程,异步执行即可。
此时使用MQ,可以在核心流程(扣减库存、生成订单记录)等完成后发送消息到MQ,快速结束本次流程。消费者拉取MQ消息时,发现红包、短信等消息时,再进行处理。
场景:双11是购物狂节,用户下单后,订单系统需要通知库存系统,传统的做法就是订单系统调用库存系统的接口
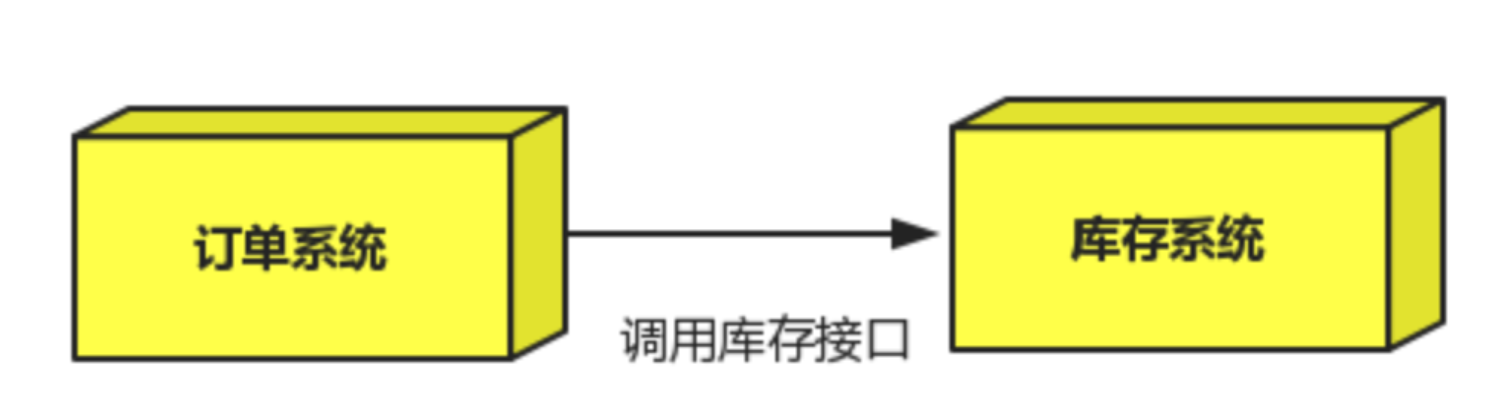
这种做法有一个缺点:
-
当库存系统出现故障时,订单就会失败。(这样马云将少赚好多好多钱钱。。。。)
-
订单系统和库存系统高耦合.
引入消息队列
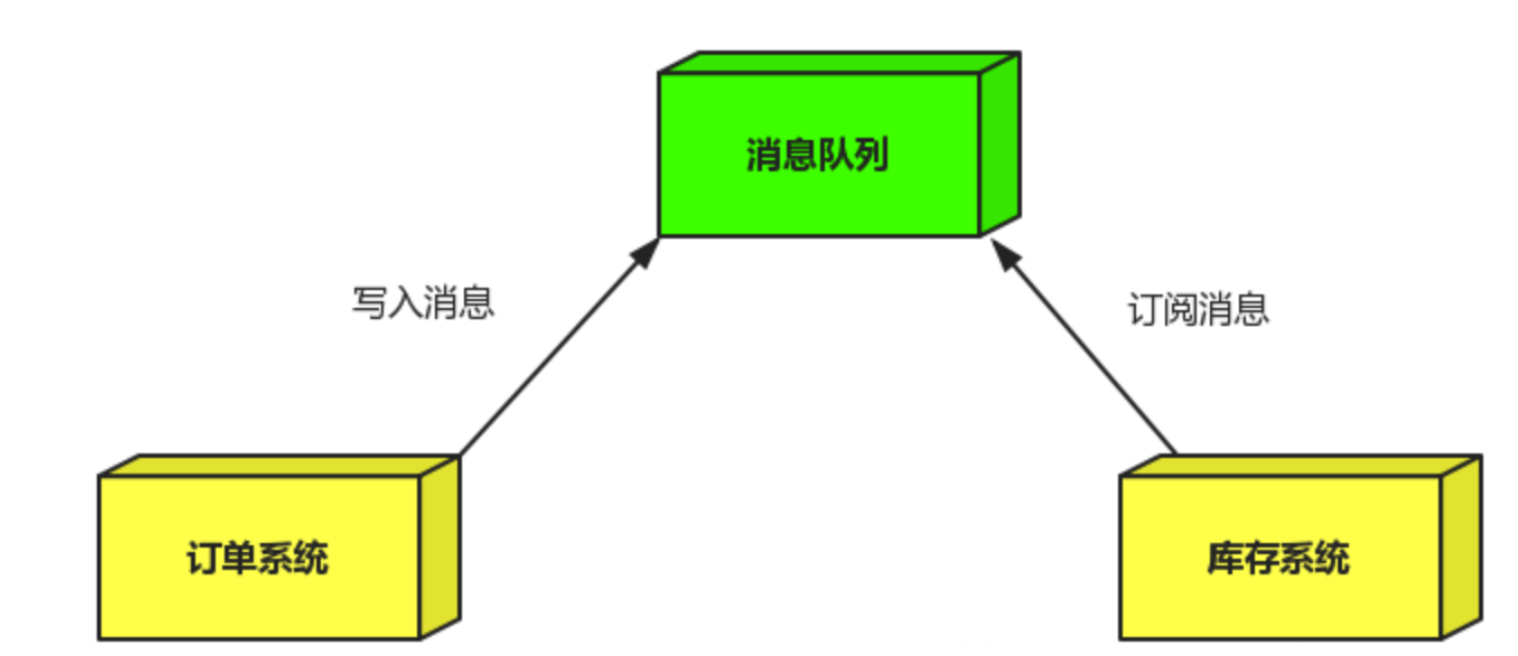
-
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
-
库存系统:订阅下单的消息,获取下单消息,进行库操作。 就算库存系统出现故障,消息队列也能保证消息的可靠投递,不会导致消息丢失(马云这下高兴了,钞票快快的来呀~~).
2.秒杀活动
流量削峰一般在秒杀活动中应用广泛 场景:秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。 作用: 1.可以控制活动人数,超过此一定阀值的订单直接丢弃(怪不得我一次秒杀都没抢到过。。。。。wtf???)
2.可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)
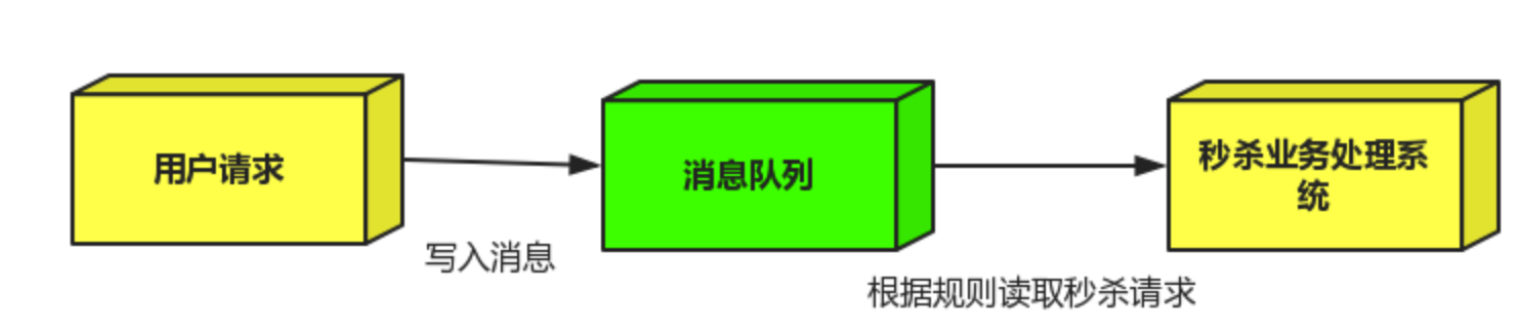
3.用户的请求,服务器接收到之后,写入消息队列,超过定义的阈值就直接丢弃请求,或者跳转错误页面。
4.业务系统取出队列中的消息,再做后续处理。
3. rabbitMQ安装
rabbitmq-server服务端1.下载centos源wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.cloud.tencent.com/repo/centos7_base.repo2.下载epel源wget -O /etc/yum.repos.d/epel.repo http://mirrors.cloud.tencent.com/repo/epel-7.repo3.清空yum缓存并且生成新的yum缓存yum clean allyum makecache4.安装erlang $ yum -y install erlang5.安装RabbitMQ $ yum -y install rabbitmq-server6.启动(无用户名密码): systemctl start/stop/restart/status rabbitmq-server设置rabbitmq账号密码,以及角色权限设置# 设置新用户yugo 密码123sudo rabbitmqctl add_user yugo 123# 设置用户为administrator角色sudo rabbitmqctl set_user_tags yugo administrator# 设置权限,允许对所有的队列都有权限 对何种资源具有配置、写、读的权限通过正则表达式来匹配,具体命令如下: set_permissions [-p] sudo rabbitmqctl set_permissions -p "/" yugo ".*" ".*" ".*"#重启服务生效设置service rabbitmq-server start/stop/restartrabbitmq相关命令// 新建用户rabbitmqctl add_user {用户名} {密码}// 设置权限rabbitmqctl set_user_tags {用户名} {权限}// 查看用户列表rabbitmqctl list_users// 为用户授权添加 Virtual Hosts : rabbitmqctl add_vhost // 删除用户rabbitmqctl delete_user Username// 修改用户的密码rabbitmqctl change_password Username Newpassword // 删除 Virtual Hosts : rabbitmqctl delete_vhost // 添加 Users : rabbitmqctl add_user rabbitmqctl set_user_tags ... rabbitmqctl set_permissions [-p ] // 删除 Users : delete_user // 使用户user1具有vhost1这个virtual host中所有资源的配置、写、读权限以便管理其中的资源rabbitmqctl set_permissions -p vhost1 user1 '.*' '.*' '.*' // 查看权限rabbitmqctl list_user_permissions user1rabbitmqctl list_permissions -p vhost1// 清除权限rabbitmqctl clear_permissions [-p VHostPath] User//清空队列步骤rabbitmqctl reset 需要提前关闭应用rabbitmqctl stop_app ,然后再清空队列,启动应用rabbitmqctl start_app此时查看队列rabbitmqctl list_queues查看所有的exchange: rabbitmqctl list_exchanges查看所有的queue: rabbitmqctl list_queues查看所有的用户: rabbitmqctl list_users查看所有的绑定(exchange和queue的绑定信息): rabbitmqctl list_bindings查看消息确认信息:rabbitmqctl list_queues name messages_ready messages_unacknowledged查看RabbitMQ状态,包括版本号等信息:rabbitmqctl status #开启web界面rabbitmq rabbitmq-plugins enable rabbitmq_management #访问web界面 http://server-name:15672/
RabbitMQ组件解释
AMQPAMQP协议是一个高级抽象层消息通信协议,RabbitMQ是AMQP协议的实现。它主要包括以下组件:
1.Server(broker): 接受客户端连接,实现AMQP消息队列和路由功能的进程。
2.Virtual Host:其实是一个虚拟概念,类似于权限控制组,一个Virtual Host里面可以有若干个Exchange和Queue,但是权限控制的最小粒度是Virtual Host
3.Exchange:接受生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由消息的行为,例如,在RabbitMQ中,ExchangeType有direct、Fanout和Topic三种,不同类型的Exchange路由的行为是不一样的。
4.Message Queue:消息队列,用于存储还未被消费者消费的消息。
5.Message: 由Header和Body组成,Header是由生产者添加的各种属性的集合,包括Message是否被持久化、由哪个Message Queue接受、优先级是多少等。而Body是真正需要传输的APP数据。
6.Binding:Binding联系了Exchange与Message Queue。Exchange在与多个Message Queue发生Binding后会生成一张路由表,路由表中存储着Message Queue所需消息的限制条件即Binding Key。当Exchange收到Message时会解析其Header得到Routing Key,Exchange根据Routing Key与Exchange Type将Message路由到Message Queue。Binding Key由Consumer在Binding Exchange与Message Queue时指定,而Routing Key由Producer发送Message时指定,两者的匹配方式由Exchange Type决定。
7.Connection:连接,对于RabbitMQ而言,其实就是一个位于客户端和Broker之间的TCP连接。
8.Channel:信道,仅仅创建了客户端到Broker之间的连接后,客户端还是不能发送消息的。需要为每一个Connection创建Channel,AMQP协议规定只有通过Channel才能执行AMQP的命令。一个Connection可以包含多个Channel。之所以需要Channel,是因为TCP连接的建立和释放都是十分昂贵的,如果一个客户端每一个线程都需要与Broker交互,如果每一个线程都建立一个TCP连接,暂且不考虑TCP连接是否浪费,就算操作系统也无法承受每秒建立如此多的TCP连接。RabbitMQ建议客户端线程之间不要共用Channel,至少要保证共用Channel的线程发送消息必须是串行的,但是建议尽量共用Connection。
9.Command:AMQP的命令,客户端通过Command完成与AMQP服务器的交互来实现自身的逻辑。例如在RabbitMQ中,客户端可以通过publish命令发送消息,txSelect开启一个事务,txCommit提交一个事务。
python客户端
// rabbitmq官方推荐的python客户端pika模块pip3 install pika
应用场景1:单发送单接收
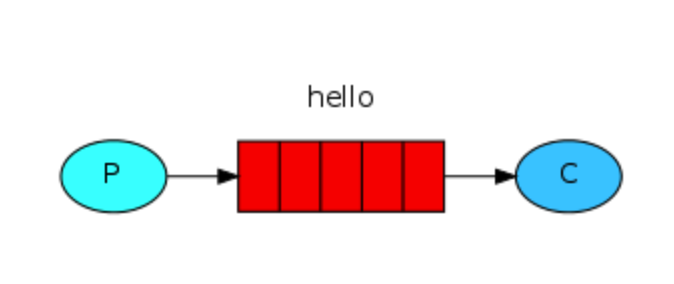
生产-消费者模型
P 是生产者 C 是消费者 中间hello是消息队列 可以有多个P、多个C P发送消息给hello队列,C消费者从队列中获取消息,默认轮询方式

生产者send.py
我们的第一个程序send.py将向队列发送一条消息。我们需要做的第一件事是建立与RabbitMQ服务器的连接。
#!/usr/bin/env pythonimport pika# 创建凭证,使用rabbitmq用户密码登录# 去邮局取邮件,必须得验证身份credentials = pika.PlainCredentials("s14","123")# 新建连接,这里localhost可以更换为服务器ip# 找到这个邮局,等于连接上服务器connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))# 创建频道# 建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接channel = connection.channel()# 声明一个队列,用于接收消息,队列名字叫“水许传”channel.queue_declare(queue='水许传')# 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据channel.basic_publish(exchange='', routing_key='水许传', body='武松又去打老虎啦2')print("已经发送了消息")# 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接connection.close() 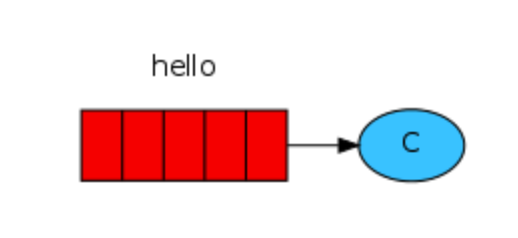
可以同时存在多个接受者,等待接收队列的消息,默认是轮训方式分配消息
接受者receive.py,可以运行多次,运行多个消费者
import pika# 建立与rabbitmq的连接credentials = pika.PlainCredentials("s14","123")connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))channel = connection.channel()channel.queue_declare(queue="水许传")def callbak(ch,method,properties,body): print("消费者接收到了任务:%r"%body.decode("utf8"))# 有消息来临,立即执行callbak,没有消息则夯住,等待消息# 老百姓开始去邮箱取邮件啦,队列名字是水许传channel.basic_consume(callbak,queue="水许传",no_ack=True)# 开始消费,接收消息channel.start_consuming()
练习:
分别启动生产者、两个消费者,往队列发送数据,查看消费者的结果
应用场景2:单发送多接收
使用场景:一个发送端,多个接收端,如分布式的任务派发。为了保证消息发送的可靠性,不丢失消息,使消息持久化了。同时为了防止接收端在处理消息时down掉,只有在消息处理完成后才发送ack消息。
rabbitmq消息确认之ack
官网资料:
默认情况下,生产者发送数据给队列,消费者取出消息后,数据将被清除。
特殊情况,如果消费者处理过程中,出现错误,数据处理没有完成,那么这段数据将从队列丢失
no-ack机制
不确认机制也就是说每次消费者接收到数据后,不管是否处理完毕,rabbitmq-server都会把这个消息标记完成,从队列中删除
ACK机制
ACK机制用于保证消费者如果拿了队列的消息,客户端处理时出错了,那么队列中仍然还存在这个消息,提供下一位消费者继续取
流程
1.生产者无须变动,发送消息2.消费者如果no_ack=True啊,数据消费后如果出错就会丢失反之no_ack=False,数据消费如果出错,数据也不会丢失3.ack机制在消费者代码中演示
生产者.py 只负责发送数据即可,无须变动
#!/usr/bin/env pythonimport pika# 创建凭证,使用rabbitmq用户密码登录# 去邮局取邮件,必须得验证身份credentials = pika.PlainCredentials("s14","123")# 新建连接,这里localhost可以更换为服务器ip# 找到这个邮局,等于连接上服务器connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))# 创建频道# 建造一个大邮箱,隶属于这家邮局的邮箱,就是个连接channel = connection.channel()# 新建一个hello队列,用于接收消息# 这个邮箱可以收发各个班级的邮件,通过channel.queue_declare(queue='金品没')# 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据channel.basic_publish(exchange='', routing_key='金品没', body='潘金莲又出去。。。')print("已经发送了消息")# 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接connection.close() 消费者.py给与ack回复
拿到消息必须给rabbitmq服务端回复ack信息,否则消息不会被删除,防止客户端出错,数据丢失
import pikacredentials = pika.PlainCredentials("s14","123")connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))channel = connection.channel()# 声明一个队列(创建一个队列)channel.queue_declare(queue='金品没')def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body.decode("utf-8")) # int('asdfasdf') # 我告诉rabbitmq服务端,我已经取走了消息 # 回复方式在这 ch.basic_ack(delivery_tag=method.delivery_tag)# 关闭no_ack,代表给与服务端ack回复,确认给与回复channel.basic_consume(callback,queue='金品没',no_ack=False)channel.start_consuming() 消息持久化
演示 1.执行生产者,向队列写入数据,产生一个新队列queue2.重启服务端,队列丢失 3.开启生产者数据持久化后,重启rabbitmq,队列不丢失 4.依旧可以读取数据
消息的可靠性是RabbitMQ的一大特色,那么RabbitMQ是如何保证消息可靠性的呢——消息持久化。 为了保证RabbitMQ在退出或者crash等异常情况下数据没有丢失,需要将queue,exchange和Message都持久化。
生产者.py
import pika# 无密码# connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61'))# 有密码credentials = pika.PlainCredentials("s14","123")connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))channel = connection.channel()# 声明一个队列(创建一个队列)# 默认此队列不支持持久化,如果服务挂掉,数据丢失# durable=True 开启持久化,必须新开启一个队列,原本的队列已经不支持持久化了'''实现rabbitmq持久化条件 delivery_mode=2使用durable=True声明queue是持久化 '''channel.queue_declare(queue='LOL',durable=True)channel.basic_publish(exchange='', routing_key='LOL', # 消息队列名称 body='德玛西亚万岁', # 支持数据持久化 properties=pika.BasicProperties( delivery_mode=2,#代表消息是持久的 2 ) )connection.close()
消费者.py
import pikacredentials = pika.PlainCredentials("s14","123")connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.119.10',credentials=credentials))channel = connection.channel()# 确保队列持久化channel.queue_declare(queue='LOL',durable=True)'''必须确保给与服务端消息回复,代表我已经消费了数据,否则数据一直持久化,不会消失'''def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body.decode("utf-8")) # 模拟代码报错 # int('asdfasdf') # 此处报错,没有给予回复,保证客户端挂掉,数据不丢失 # 告诉服务端,我已经取走了数据,否则数据一直存在 ch.basic_ack(delivery_tag=method.delivery_tag)# 关闭no_ack,代表给与回复确认channel.basic_consume(callback,queue='LOL',no_ack=False)channel.start_consuming()
Exchange模型
rabbitmq发送消息首先是发给exchange,然后再通过exchange发送消息给队列(queue)
exchange有四种模式
fanout
exchange将消息发送给和该exchange连接的所有queue;也就是所谓的广播模式;此模式下忽略routing_key;
direct
路由模式,通过routing_key将消息发送给对应的queue; 如下面这句即可设置exchange为direct模式,只有routing_key为“black”时才将其发送到队列queue_name;channel.queue_bind(exchange=exchange_name,queue=queue_name,routing_key='black')
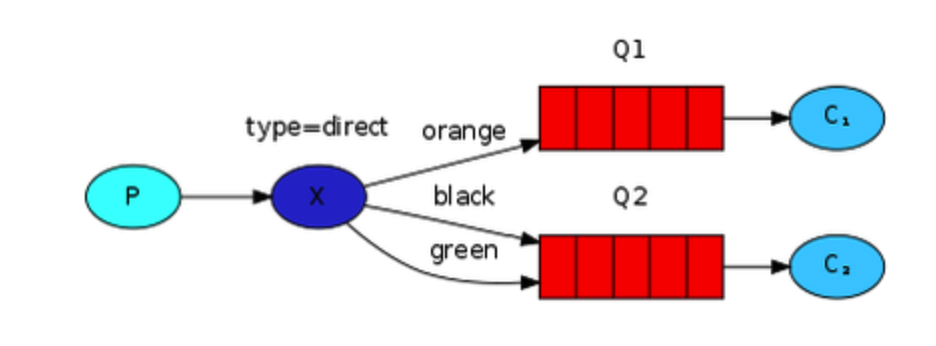
在上图中,Q1和Q2可以绑定同一个key,如绑定routing_key=‘KeySame’,那么收到routing_key为KeySame的消息时将会同时发送给Q1和Q2,退化为广播模式;
top
topic模式类似于direct模式,只是其中的routing_key变成了一个有“.”分隔的字符串,“.”将字符串分割成几个单词,每个单词代表一个条件;
headers
headers类型的Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
官方教程:
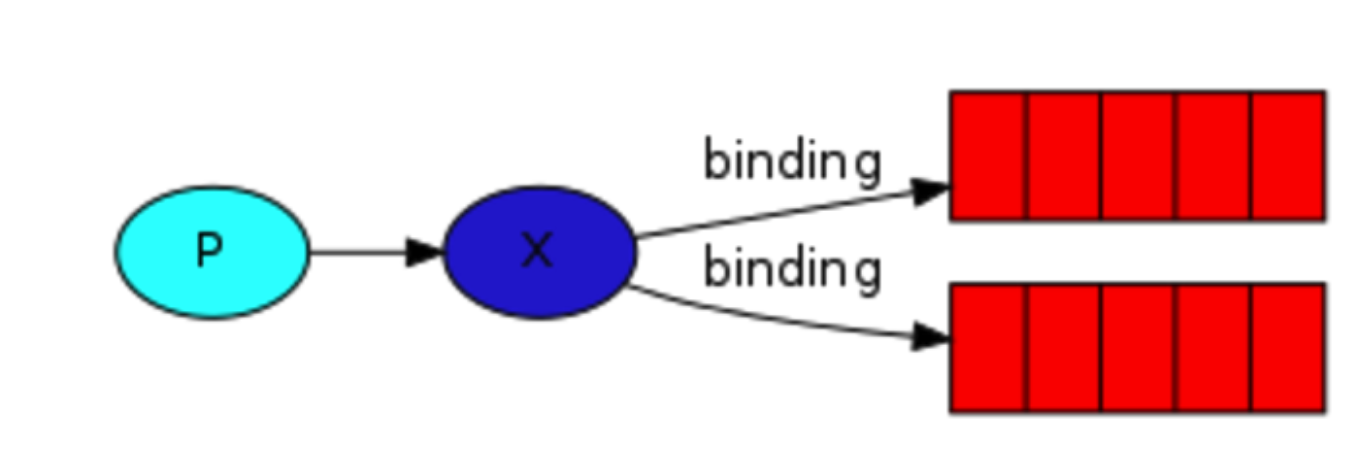
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
# fanout所有的队列放一份/给某些队列发 # 传送消息的模式 # 与exchange有关的模式都发 exchange_type = fanout
消费者_订阅.py
可以运行多次,运行多个消费者,等待消息
import pika credentials = pika.PlainCredentials("root","123") connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials)) channel = connection.channel() # exchange='m1',exchange(秘书)的名称 # exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列 channel.exchange_declare(exchange='m1',exchange_type='fanout') # 随机生成一个队列 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 让exchange和queque进行绑定. channel.queue_bind(exchange='m1',queue=queue_name) def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) channel.basic_consume(callback,queue=queue_name,no_ack=True) channel.start_consuming() 生产者_发布者.py
# -*- coding: utf-8 -*- # __author__ = "yugo" import pika credentials = pika.PlainCredentials("root","123") connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials)) channel = connection.channel() # 指定exchange channel.exchange_declare(exchange='m1',exchange_type='fanout') channel.basic_publish(exchange='m1', routing_key='',# 这里不再指定队列,由exchange分配,如果是fanout模式,每一个队列放一份 body='haohaio') connection.close() 实例
1.可以运行多个消费者,相当于有多个滴滴司机,等待着Exchange同一个电台发消息2.运行发布者,发送消息给Exchange,查看是否给所有的队列(滴滴司机)发送了消息
关键字发布Exchange
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。

消费者1.py
路由关键字是sb,alex
# -*- coding: utf-8 -*- # __author__ = "maple" import pika credentials = pika.PlainCredentials("root","123") connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials)) channel = connection.channel() # exchange='m1',exchange(秘书)的名称 # exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列 channel.exchange_declare(exchange='m2',exchange_type='direct') # 随机生成一个队列,队列退出时,删除这个队列 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 让exchange和queque进行绑定,只要 channel.queue_bind(exchange='m2',queue=queue_name,routing_key='alex') channel.queue_bind(exchange='m2',queue=queue_name,routing_key='sb') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) channel.basic_consume(callback,queue=queue_name,no_ack=True) channel.start_consuming() 消费者2.py
路由关键字sb
# -*- coding: utf-8 -*- # __author__ = "maple" import pika credentials = pika.PlainCredentials("root","123") connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials)) channel = connection.channel() # exchange='m1',exchange(秘书)的名称 # exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列 channel.exchange_declare(exchange='m2',exchange_type='direct') # 随机生成一个队列 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 让exchange和queque进行绑定. channel.queue_bind(exchange='m2',queue=queue_name,routing_key='sb') def callback(ch, method, properties, body): print("消费者接受到了任务: %r" % body) channel.basic_consume(callback,queue=queue_name,no_ack=True) channel.start_consuming() 生产者.py
发送消息给匹配的路由,sb或者alex
# -*- coding: utf-8 -*- # __author__ = "yugo" import pika credentials = pika.PlainCredentials("root","123") connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials)) channel = connection.channel() # 路由模式的交换机会发送给绑定的key和routing_key匹配的队列 channel.exchange_declare(exchange='m2',exchange_type='direct') # 发送消息,给有关sb的路由关键字 channel.basic_publish(exchange='m2', routing_key='sb', body='aaaalexlaolelaodi') connection.close() RPC之远程过程调用
将一个函数运行在远程计算机上并且等待获取那里的结果,这个称作远程过程调用(Remote Procedure Call)或者 RPC。
RPC是一个计算机通信协议。
比喻
将计算机服务运行理解为厨师做饭,厨师想做一个小葱拌豆腐,厨师需要洗小葱、切豆腐、调汁、凉拌。他一个人完成所有的事,如同古老的集中式应用,一台计算机做所有的事。 制作小葱拌豆腐{ 厨师>洗小葱>切豆腐>凉拌 } rpc应用场景
而如今,饭店做大了,有钱了,专职分工来干活,不再是厨师单打独斗,备菜师傅准备小葱、豆腐,切菜师傅切小葱、豆腐,厨师只负责调味,完成食品。 制作小葱拌豆腐{ 备菜师>洗菜 切菜师>切菜 厨师>调味 } 此时一件事好多人在做,厨师就得和其他人沟通,通知备菜、洗菜师傅的这个动作就是远程过程调用(RPC)。
这个过程在计算机系统中,一个电商的下单过程,涉及物流、支付、库存、红包等多个系统,多个系统又在多个服务器上,由不同的技术团队负责,整个下单过程,需要所有团队进行远程调用。
下单{ 库存>减少库存 支付>扣款 红包>减免红包 物流>生成订单 } 到底什么是rpc
rpc指的是在计算机A上的进程,调用另外一台计算机B的进程,A上的进程被挂起,B上的被调用进程开始执行后,产生返回值给A,A继续执行。 调用方可以通过参数将信息传递给被调用方,而后通过返回结果得到信息,这个过程对于开发人员来说是透明的。 如同厨师一样,服务员把菜单给后厨,厨师告诉洗菜人,备菜人,开始工作,完成工作后,整个过程对于服务员是透明的,他完全不用管后厨是怎么把菜做好的。
由于服务在不同的机器上,远程调用必经网络通信,调用服务必须写一坨网络通信代码,很容易出错且很复杂,因此就出现了RPC框架。
阿里巴巴的 Dubbo java 新浪的 Motan java 谷歌的 gRPC 多语言 Apache thrift 多语言
rpc封装了数据的序列化,反序列化,以及传输协议
python实现RPC
利用RabbitMQ构建一个RPC系统,包含了客户端和RPC服务器,依旧使用pika模块
Callback queue 回调队列
一个客户端向服务器发送请求,服务器端处理请求后,将其处理结果保存在一个存储体中。而客户端为了获得处理结果,那么客户在向服务器发送请求时,同时发送一个回调队列地址reply_to。
Correlation id 关联标识
一个客户端可能会发送多个请求给服务器,当服务器处理完后,客户端无法辨别在回调队列中的响应具体和那个请求时对应的。为了处理这种情况,客户端在发送每个请求时,同时会附带一个独有correlation_id属性,这样客户端在回调队列中根据correlation_id字段的值就可以分辨此响应属于哪个请求。
客户端发送请求:某个应用将请求信息交给客户端,然后客户端发送RPC请求,在发送RPC请求到RPC请求队列时,客户端至少发送带有reply_to以及correlation_id两个属性的信息 服务器端工作流: 等待接受客户端发来RPC请求,当请求出现的时候,服务器从RPC请求队列中取出请求,然后处理后,将响应发送到reply_to指定的回调队列中 客户端接受处理结果: 客户端等待回调队列中出现响应,当响应出现时,它会根据响应中correlation_id字段的值,将其返回给对应的应用 过程
1.启动rpc客户端,等待接收数据到来,来了之后就进行处理,再将结果丢进队列2.启动rpc服务端,发起请求
rpc_server.py
import pika import uuid class FibonacciRpcClient(object): def __init__(self): # 客户端启动时,创建回调队列,会开启会话用于发送RPC请求以及接受响应 # 建立连接,指定服务器的ip地址 self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.119.10')) # 建立一个会话,每个channel代表一个会话任务 self.channel = self.connection.channel() # 声明回调队列,再次声明的原因是,服务器和客户端可能先后开启,该声明是幂等的,多次声明,但只生效一次 #exclusive=True 参数是指只对首次声明它的连接可见 #exclusive=True 会在连接断开的时候,自动删除 result = self.channel.queue_declare(exclusive=True) # 将次队列指定为当前客户端的回调队列 self.callback_queue = result.method.queue # 客户端订阅回调队列,当回调队列中有响应时,调用`on_response`方法对响应进行处理; self.channel.basic_consume(self.on_response, no_ack=True, queue=self.callback_queue) # 对回调队列中的响应进行处理的函数 def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body # 发出RPC请求 # 例如这里服务端就是一个切菜师傅,菜切好了,需要传递给洗菜师傅,这个过程是发送rpc请求 def call(self, n): # 初始化 response self.response = None # 生成correlation_id 关联标识,通过python的uuid库,生成全局唯一标识ID,保证时间空间唯一性 self.corr_id = str(uuid.uuid4()) # 发送RPC请求内容到RPC请求队列`s14rpc`,同时发送的还有`reply_to`和`correlation_id` self.channel.basic_publish(exchange='', routing_key='s14rpc', properties=pika.BasicProperties( reply_to=self.callback_queue, correlation_id=self.corr_id, ), body=str(n)) while self.response is None: self.connection.process_data_events() return int(self.response) # 建立客户端 fibonacci_rpc = FibonacciRpcClient() # 发送RPC请求,丢进rpc队列,等待客户端处理完毕,给与响应 print("发送了请求sum(99)") response = fibonacci_rpc.call(99) print("得到远程结果响应%r" % response)
rpc_client.py
import pika # 建立连接,服务器地址为localhost,可指定ip地址 connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.119.10')) # 建立会话 channel = connection.channel() # 声明RPC请求队列 channel.queue_declare(queue='s14rpc') # 模拟一个进程,例如切菜师傅,等着洗菜师傅传递数据 def sum(n): n+=100 return n # 对RPC请求队列中的请求进行处理 def on_request(ch, method, props, body): print(body,type(body)) n = int(body) print(" 正在处理sum(%s)" % n) # 调用数据处理方法 response = sum(n) # 将处理结果(响应)发送到回调队列 ch.basic_publish(exchange='', # reply_to代表回复目标 routing_key=props.reply_to, # correlation_id(关联标识):用来将RPC的响应和请求关联起来。 properties=pika.BasicProperties(correlation_id= \ props.correlation_id), body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag) # 负载均衡,同一时刻发送给该服务器的请求不超过一个 channel.basic_qos(prefetch_count=1) channel.basic_consume(on_request, queue='s14rpc') print("等待接收rpc请求") #开始消费 channel.start_consuming()